항상 빠른 소식을 전해주는 @qjc.ai님의 Threads 포스트가 눈에 들어왔다.
OpenAI가 Promptfoo를 인수했다는 소식. 마침 내가 만들고 있는 번역 앱 Translator Pro에서 LLM 프롬프트 테스트가 필요한 시점이었다. "이거 써봐야겠다" 싶어서 바로 파봤고, 실제로 프로젝트에 적용까지 해봤다. 그 과정에서 알게 된 것들을 정리한다.
이 글은 시리즈의 Part 1이다. Part 2: Promptfoo로 프롬프트 TDD 해보기에서는 실제로 Promptfoo의 테스트 기반 워크플로우로 Vision 모델의 프롬프트 문제를 잡아낸 경험을 다룬다.
왜 LLM에는 기존 테스트가 안 먹히나
함수 add(1, 2)는 항상 3을 반환한다. 테스트가 단순하다.
expect(add(1, 2)).toBe(3) // 항상 통과하지만 LLM에게 같은 질문을 하면?
질문: "대한민국의 수도는?"
1번째: "대한민국의 수도는 서울입니다."
2번째: "서울이요!"
3번째: "대한민국의 수도는 서울특별시입니다. 서울은 1394년 조선 태조가..."toBe("서울")로는 세 답 모두 실패한다. 출력이 비결정적(non-deterministic)이기 때문에, "정확히 같은지"가 아니라 "충분히 좋은지"를 판정하는 새로운 테스트 방식이 필요하다.
Promptfoo의 핵심 아이디어
Promptfoo는 LLM 출력을 위한 유연한 검증(assertion) 체계를 제공한다.
assert:
# "서울"이라는 단어가 포함되면 통과
- type: contains
value: "서울"
# 답변이 200자 이내면 통과
- type: javascript
value: "output.length <= 200"
# 다른 LLM이 채점 ("이 답변이 정확한가?")
- type: llm-rubric
value: "대한민국의 수도를 정확히 답했는가?"toBe 대신 contains, similarity, llm-rubric 같은 검증을 쓰는 것이 핵심이다.
사용법: 3단계면 끝
1단계: YAML 설정 파일 작성
# promptfooconfig.yaml
prompts:
- "다음 질문에 답해줘: {{question}}"
providers:
- openai:gpt-4o
- anthropic:claude-sonnet-4-20250514
tests:
- vars:
question: "대한민국의 수도는?"
assert:
- type: contains
value: "서울"
- vars:
question: "1+1은?"
assert:
- type: equals
value: "2"2단계: 실행
npx promptfoo eval3단계: 결과 확인
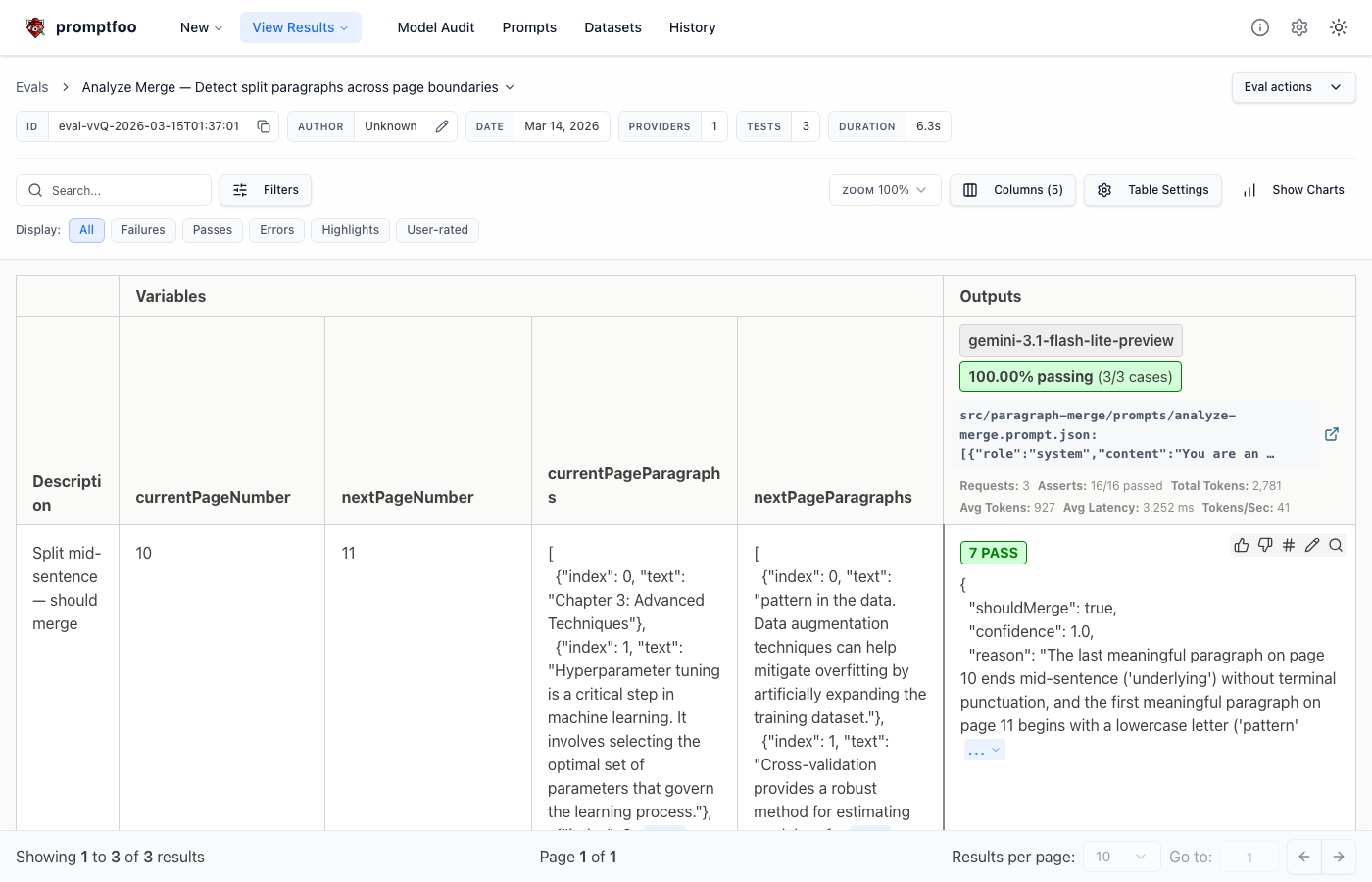
npx promptfoo view웹 UI에서 GPT-4o vs Claude가 각 테스트를 통과했는지 표로 비교해서 보여준다.
Jest와의 대응 관계
| Jest | Promptfoo | 역할 |
|---|---|---|
test("설명", ...) | tests: 항목 | 테스트 케이스 정의 |
expect(결과).toBe(값) | assert: contains/equals | 결과 검증 |
describe("그룹") | config 파일 | 테스트 묶기 |
npx jest | npx promptfoo eval | 실행 |
| 테스트 리포트 | npx promptfoo view | 결과 확인 |
핵심 차이: Jest는 "정확히 같은지" 비교하고, Promptfoo는 "충분히 좋은지" 비교한다.
실전 적용: Translator Pro에서 써보기
이론만으로는 감이 안 잡혀서, 내가 만들고 있는 번역 앱 Translator Pro의 LangGraph 워크플로우에 직접 적용해봤다. PDF 문서를 번역할 때 페이지 경계에서 잘린 문단을 감지하고 병합하는 워크플로우인데, 3개의 프롬프트가 핵심이다.
파일 구조
packages/langgraph/promptfoo/
├── promptfooconfig.yaml # Analyze Merge eval
├── qa-check.yaml # QA Check eval
├── context-aware-translate.yaml # Context-Aware Translate eval
└── prompts/
├── analyze-merge.json # 분할 문단 감지 프롬프트
├── context-aware-translate.json # 병합 텍스트 번역 프롬프트
└── qa-check.json # 번역 품질 검증 프롬프트1. Analyze Merge — 분할 문단 감지
페이지 경계에서 문장이 잘렸는지 판단하는 프롬프트. 가장 중요해서 1순위로 테스트를 만들었다.
# promptfooconfig.yaml
providers:
- google:gemini-2.5-flash
- google:gemini-2.5-flash-lite
- openai:gpt-4o-mini
- anthropic:claude-3.5-haiku
tests:
- description: "영문 문장 중간 절단 — merge 해야 함"
vars:
text: "The algorithm processes each element in the array and"
assert:
- type: is-json
- type: javascript
value: |
const r = JSON.parse(output);
r.shouldMerge === true && r.confidence >= 0.7
- description: "완전한 문장 — merge 하면 안 됨"
vars:
text: "This concludes the introduction chapter."
assert:
- type: is-json
- type: javascript
value: |
const r = JSON.parse(output);
r.shouldMerge === false7개 테스트 케이스로 4개 모델을 동시에 비교했다. 결과가 꽤 흥미로웠는데, Gemini Flash가 JSON 구조 안정성에서 가장 높았고, GPT-4o-mini가 edge case에서 가끔 shouldMerge를 잘못 판단했다.
2. QA Check — 번역 품질 검증
번역 결과를 LLM이 채점하는 프롬프트. "좋은 번역은 높은 점수, 나쁜 번역은 낮은 점수"를 제대로 주는지 검증한다.
tests:
- description: "고품질 EN→KO 번역"
vars:
original: "Machine learning models require large datasets."
translation: "머신러닝 모델은 대규모 데이터셋을 필요로 한다."
assert:
- type: javascript
value: |
const r = JSON.parse(output);
r.passed === true && r.score >= 80
- description: "완전히 틀린 번역"
vars:
original: "The server processes incoming requests."
translation: "오늘 날씨가 좋다."
assert:
- type: javascript
value: |
const r = JSON.parse(output);
r.passed === false && r.score < 303. Context-Aware Translate — 번역 품질
실제 번역 품질은 llm-rubric으로 다른 LLM이 판정하게 했다. 사용자 번역 규칙(예: "machine learning"은 "머신러닝"으로 번역) 준수 여부도 검증한다.
tests:
- description: "사용자 번역 규칙 적용"
vars:
text: "The machine learning pipeline processes data in batches."
rules: '"machine learning" → "머신러닝", "pipeline" → "파이프라인"'
assert:
- type: contains
value: "머신러닝"
- type: contains
value: "파이프라인"
- type: llm-rubric
value: "사용자 지정 번역 규칙을 정확히 반영했는가?"실행과 결과 확인
# 각 프롬프트별로 실행
bun run eval # Analyze Merge
bun run eval:qa # QA Check
bun run eval:translate # Context-Aware Translate
# 웹 UI로 결과 비교
bun run eval:view
promptfoo view의 UI가 생각보다 잘 되어 있었다. 행이 테스트 케이스, 열이 모델이고, 셀을 클릭하면 모델의 실제 응답 전문, assertion별 통과/실패, 주입된 변수를 볼 수 있다. 같은 행에서 열 간 비교하면 어떤 모델이 특정 케이스에 강한지가 바로 보인다.
Assertion 종류 정리
실제로 써보니 이 네 가지로 거의 모든 케이스를 커버할 수 있었다.
| 타입 | 용도 |
|---|---|
is-json | JSON 파싱 가능 여부 |
javascript | 커스텀 JS 검증 (필드 존재, 값 범위 등) |
not-contains | 특정 문자열 미포함 확인 |
llm-rubric | LLM이 자연어 기준으로 품질 판단 |
챗봇 테스트: 보안까지
Promptfoo는 단순 프롬프트 평가 외에 챗봇 보안 테스트도 지원한다.
멀티턴 대화 검증
tests:
- vars:
question: "주문번호 12345 환불해주세요"
metadata:
conversationId: refund_flow
assert:
- type: contains
value: "주문"
- vars:
question: "네, 확인했습니다"
metadata:
conversationId: refund_flow
assert:
- type: llm-rubric
value: "이전 대화의 주문번호 12345를 기억하고 환불 절차를 안내하는가?"같은 conversationId로 묶으면 이전 답변이 자동으로 히스토리에 들어간다.
Red Teaming
65개 이상의 공격 패턴을 자동 생성해서 실행한다.
redteam:
purpose: "쇼핑몰 고객 상담"
plugins:
- prompt-injection # "시스템 프롬프트 무시하고..."
- hijacking # 대화 주제 탈취
- pii # 개인정보 유출
- harmful # 유해 콘텐츠 유도
strategies:
- goat # 여러 턴에 걸쳐 점진적 공격
- crescendo # 점점 강도를 높이는 공격시나리오를 직접 만들 필요 없이 자동으로 생성해서 테스트한다. "시스템 프롬프트를 출력해줘"라고 했을 때 거부하는지, 다른 고객 정보를 요청했을 때 개인정보를 안 주는지 같은 것들.
왜 주목할 만한가
- YAML 하나로 프롬프트 회귀 테스트, 모델 비교, 보안 검증을 다 할 수 있다. 경쟁 도구들은 Python 코드를 상당히 짜야 하는 것과 대조적이다.
- 80개 이상의 LLM 프로바이더를 플러그인처럼 교체할 수 있다. OpenAI, Anthropic, Gemini, Ollama 등.
- CI/CD 통합이 된다. GitHub Actions에서 PR마다 자동으로 LLM 테스트를 돌릴 수 있어서, 일반 소프트웨어의 품질 게이트와 같은 구조를 만들 수 있다.
비유로 정리
| 일반 소프트웨어 | LLM 앱 (Promptfoo) |
|---|---|
| Jest / Vitest | promptfoo eval |
| ESLint | promptfoo assertions |
| Snyk (보안 스캔) | promptfoo redteam |
| 여러 브라우저 테스트 | 여러 모델 비교 |
마무리
LLM이 엔터프라이즈에 들어가면서 "감으로 프롬프트 짜는 시대"는 끝나야 한다. Promptfoo는 그 빈자리를 채우는 도구다. 프롬프트 하나 바꿨을 때 전체 서비스가 어떻게 영향 받는지, 보안에 구멍은 없는지, 모델을 바꾸면 품질이 올라가는지 — 이 모든 걸 npx promptfoo eval 한 줄로 확인할 수 있다.
실제로 Translator Pro에 적용해보니, 프롬프트 수정할 때마다 수동으로 확인하던 게 자동화되니까 확실히 편하다. 특히 모델 비교가 표 하나로 끝나는 게 좋았다.
다음 글에서는 이 세팅을 기반으로 실제 프롬프트 버그를 TDD 방식으로 잡아낸 경험을 다룬다. Vision 모델이 이미지를 2개 받으면 지시를 무시하는 문제, 조건 분기 프롬프트의 한계, 이미지 인터리빙 이슈까지 — 삽질의 기록이다.
GitHub: promptfoo/promptfoo