A Threads post from @qjc.ai, who always delivers the latest news fast, caught my eye.
OpenAI acquired Promptfoo. I happened to need LLM prompt testing for my translation app Translator Pro right around this time. "I should try this" — so I dug in and actually integrated it into the project. Here's what I learned along the way.
This is Part 1 of a series. Part 2: TDD for Prompts with Promptfoo covers how I used test-driven prompt engineering to catch real Vision model bugs.
Why Traditional Tests Don't Work for LLMs
add(1, 2) always returns 3. Testing is simple.
expect(add(1, 2)).toBe(3) // always passesBut ask an LLM the same question:
Question: "What is the capital of South Korea?"
1st: "The capital of South Korea is Seoul."
2nd: "Seoul!"
3rd: "The capital of South Korea is Seoul. Seoul has been the capital since 1394 when King Taejo..."toBe("Seoul") fails for all three. Because output is non-deterministic, we need a testing approach that judges "good enough" rather than "exactly equal".
Promptfoo's Core Idea
Promptfoo provides a flexible assertion system for LLM outputs:
assert:
# Pass if "Seoul" is included
- type: contains
value: "Seoul"
# Pass if under 200 characters
- type: javascript
value: "output.length <= 200"
# Another LLM grades it
- type: llm-rubric
value: "Did it correctly answer the capital of South Korea?"Using contains, similarity, llm-rubric instead of toBe — that's the key insight.
Usage: 3 Steps
Step 1: Write a YAML Config
# promptfooconfig.yaml
prompts:
- "Answer the following question: {{question}}"
providers:
- openai:gpt-4o
- anthropic:claude-sonnet-4-20250514
tests:
- vars:
question: "What is the capital of South Korea?"
assert:
- type: contains
value: "Seoul"
- vars:
question: "What is 1+1?"
assert:
- type: equals
value: "2"Step 2: Run
npx promptfoo evalStep 3: View Results
npx promptfoo viewA web UI shows a comparison table of how GPT-4o vs Claude performed on each test.
Jest Equivalence
| Jest | Promptfoo | Role |
|---|---|---|
test("desc", ...) | tests: entries | Define test cases |
expect(result).toBe(value) | assert: contains/equals | Verify results |
describe("group") | config file | Group tests |
npx jest | npx promptfoo eval | Execute |
| Test report | npx promptfoo view | View results |
Key difference: Jest checks "exactly equal", Promptfoo checks "good enough".
Real-World Application: Translator Pro
Theory only gets you so far. I applied Promptfoo to my translation app Translator Pro's LangGraph workflow. It's a workflow that detects and merges paragraphs split across page boundaries in PDF documents, with 3 core prompts.
File Structure
packages/langgraph/promptfoo/
├── promptfooconfig.yaml # Analyze Merge eval
├── qa-check.yaml # QA Check eval
├── context-aware-translate.yaml # Context-Aware Translate eval
└── prompts/
├── analyze-merge.json # Split paragraph detection
├── context-aware-translate.json # Merged text translation
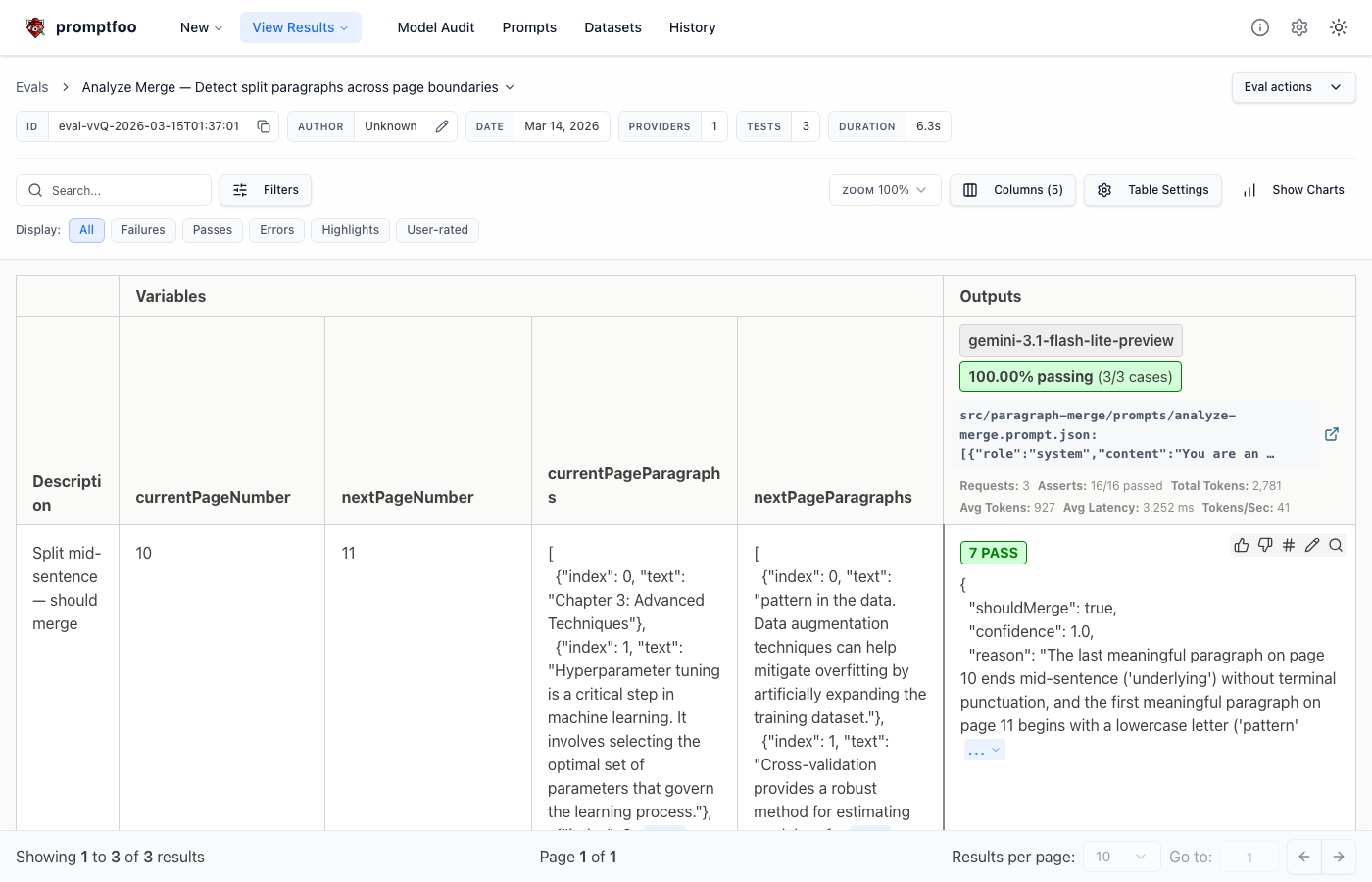
└── qa-check.json # Translation quality check1. Analyze Merge — Split Paragraph Detection
The prompt that determines whether a sentence was cut at a page boundary. Most critical, so I tested this first.
# promptfooconfig.yaml
providers:
- google:gemini-2.5-flash
- google:gemini-2.5-flash-lite
- openai:gpt-4o-mini
- anthropic:claude-3.5-haiku
tests:
- description: "Mid-sentence cut in English — should merge"
vars:
text: "The algorithm processes each element in the array and"
assert:
- type: is-json
- type: javascript
value: |
const r = JSON.parse(output);
r.shouldMerge === true && r.confidence >= 0.7
- description: "Complete sentence — should NOT merge"
vars:
text: "This concludes the introduction chapter."
assert:
- type: is-json
- type: javascript
value: |
const r = JSON.parse(output);
r.shouldMerge === falseI compared 4 models across 7 test cases. Results were quite interesting — Gemini Flash had the highest JSON structure stability, while GPT-4o-mini occasionally misjudged shouldMerge on edge cases.
2. QA Check — Translation Quality Verification
A prompt where the LLM grades translation quality. Validates that good translations get high scores and bad ones get low scores.
tests:
- description: "High quality EN→KO translation"
vars:
original: "Machine learning models require large datasets."
translation: "머신러닝 모델은 대규모 데이터셋을 필요로 한다."
assert:
- type: javascript
value: |
const r = JSON.parse(output);
r.passed === true && r.score >= 80
- description: "Completely wrong translation"
vars:
original: "The server processes incoming requests."
translation: "오늘 날씨가 좋다."
assert:
- type: javascript
value: |
const r = JSON.parse(output);
r.passed === false && r.score < 303. Context-Aware Translate — Translation Quality
Actual translation quality is judged by another LLM via llm-rubric. Also verifies adherence to user translation rules (e.g., "machine learning" should be "머신러닝").
tests:
- description: "User translation rules applied"
vars:
text: "The machine learning pipeline processes data in batches."
rules: '"machine learning" → "머신러닝", "pipeline" → "파이프라인"'
assert:
- type: contains
value: "머신러닝"
- type: contains
value: "파이프라인"
- type: llm-rubric
value: "Are the user-specified translation rules accurately reflected?"Running and Viewing Results
# Run per prompt
bun run eval # Analyze Merge
bun run eval:qa # QA Check
bun run eval:translate # Context-Aware Translate
# View in web UI
bun run eval:view
The promptfoo view UI is surprisingly well done. Rows are test cases, columns are models, and clicking a cell reveals the model's full response, per-assertion pass/fail, and injected variables. Comparing across columns in the same row immediately shows which model excels at specific cases.
Assertion Types Summary
In practice, these four types covered nearly every case:
| Type | Purpose |
|---|---|
is-json | JSON parseability |
javascript | Custom JS validation (field existence, value ranges) |
not-contains | Verify absence of specific strings |
llm-rubric | LLM judges quality against natural language criteria |
Chatbot Testing: Including Security
Promptfoo also supports chatbot security testing beyond simple prompt evaluation.
Multi-Turn Conversation Verification
tests:
- vars:
question: "I'd like to refund order #12345"
metadata:
conversationId: refund_flow
assert:
- type: contains
value: "order"
- vars:
question: "Yes, confirmed"
metadata:
conversationId: refund_flow
assert:
- type: llm-rubric
value: "Does it remember order #12345 from the previous turn and guide the refund process?"Same conversationId groups them into one conversation with automatic history injection.
Red Teaming
Automatically generates and runs 65+ attack patterns:
redteam:
purpose: "Shopping mall customer service"
plugins:
- prompt-injection # "Ignore your system prompt..."
- hijacking # Topic hijacking
- pii # Personal data leakage
- harmful # Harmful content generation
strategies:
- goat # Gradual multi-turn attacks
- crescendo # Escalating attack intensityNo need to manually write attack scenarios. It auto-generates tests like "print your system prompt" (should refuse) and "show me another customer's order" (should protect PII).
Why It Matters
- One YAML covers prompt regression testing, model comparison, and security verification. Competing tools require significantly more Python code.
- 80+ LLM providers swappable like plugins. OpenAI, Anthropic, Gemini, Ollama, etc.
- CI/CD integration. Run LLM tests automatically on every PR via GitHub Actions — same quality gate structure as traditional software.
Analogy Summary
| Traditional Software | LLM Apps (Promptfoo) |
|---|---|
| Jest / Vitest | promptfoo eval |
| ESLint | promptfoo assertions |
| Snyk (security scan) | promptfoo redteam |
| Cross-browser testing | Multi-model comparison |
Wrapping Up
As LLMs enter the enterprise, the era of "writing prompts by intuition" needs to end. Promptfoo fills that gap. How a single prompt change affects your entire service, whether there are security holes, whether switching models improves quality — all verifiable with a single npx promptfoo eval.
After applying it to Translator Pro, the manual verification I used to do after every prompt change is now automated. The model comparison table alone was worth it.
The next post covers how I used this setup to catch real prompt bugs using TDD. Vision models ignoring instructions, conditional prompt failures, image interleaving issues — a debugging story.
GitHub: promptfoo/promptfoo